
VOIS#NLP
- 인간의 언어를 컴퓨터가 이해할 수 있도록 처리하는 기술: 자연어 분석, 이해, 대화 관리, 발화 생성
- 정규 문법, 사전 정보를 활용하여 형태소 분석, 품사 인식, 구문 분석, 의미 추론 수행
- ML/DL 기술을 활용한 검색, 문장 분류, 개체명 인식, 질의응답, 답변 생성 기능 구현
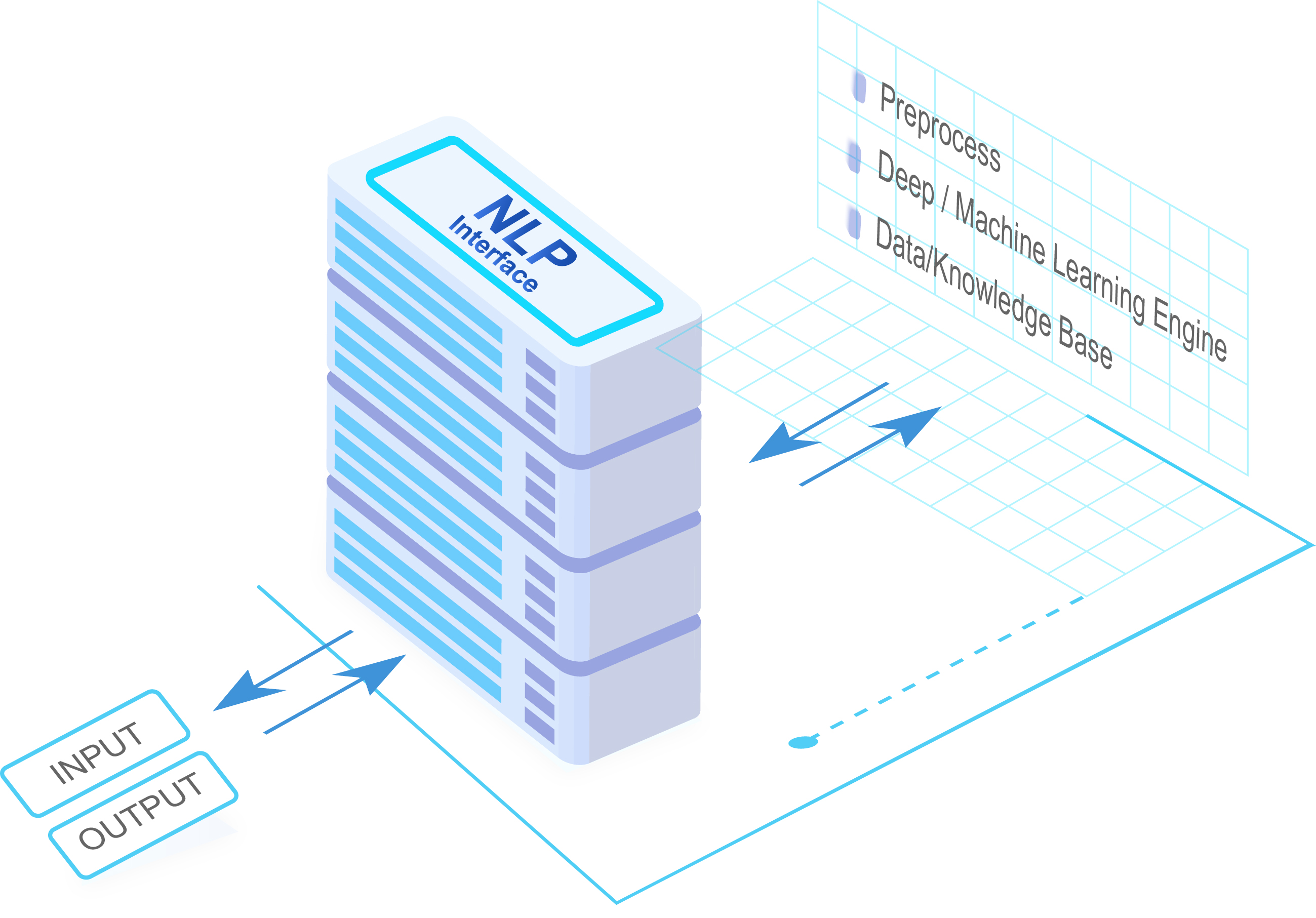
1.
Preprocess
전처리: 맞춤법 교정, 문장 분리, 문자열 정제 등을 수행합니다.
형태소 분석: 문장으로부터 명사, 동사, 조사 등을 분리합니다.
구문 분석: 분석된 형태소를 기반으로 문장의 구조를 결정합니다.
2.
Deep/Machine Learning Engine
문장 분류: 문장의 의도가 어떤 카테고리에 속하는 지 분류합니다.
개체명 인식: 문장으로부터 핵심 단어를 추출합니다.
질의응답: 질문에 대한 답을 지문에서 찾아 답변합니다.
문장 생성: 입력 문장 다음에 올 자연스러운 대화를 생성합니다.
3.
Data/Knowledge Base
데이터베이스: 학습데이터, 규칙 사전, 대화 패턴 등을 저장합니다.
의미 분석 알고리즘: 적절한 응답을 제시할 수 있도록 의미를 추론합니다.
대화 관리 알고리즘: 현재 대화 상태를 분석해 맥락에 맞는 다음 대화를 유도합니다.