음성을 이용한 화자인식 기술은 음성에 포함된 언어적 정보뿐 아니라 발화자 특성 정보(Voice-print)를 이용하여 생체 보안 분야에 사용되는 기술입니다. 또한, 지능형 로봇 분야와 스마트 가전 분야의 개인 특화형 맞춤 서비스에 필수 요소 기술로 사용되고 있습니다.
핵심 알고리즘
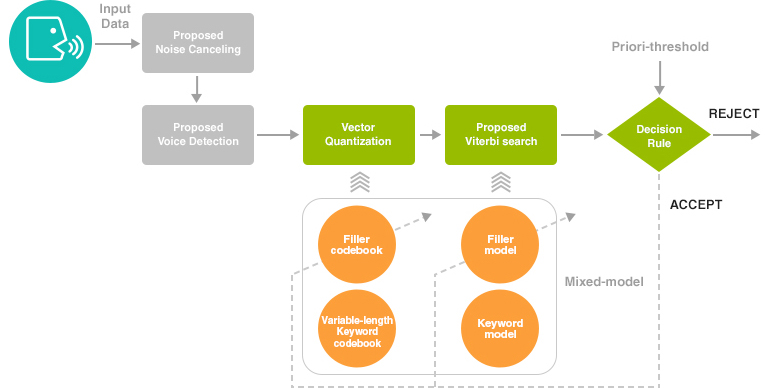
Adaptive component weighting을 이용한 화자별 음성 특징 파라미터 추출 알고리즘을 통해 화자간 변별력을 최대화하고, 음성정보를 최소화하고 생체 정보를 최대화하는 혼합모델 VQ/HMM 화자 판별 알고리즘을 개발, 화자 적응 기술과 Signal bias removal 알고리즘을 적용하여 소량의 학습 데이터만으로도 잡음에 강인한 화자인식 시스템을 개발합니다.
- Inter-Speaker Variation Minimization
- 화자간 변별력 향상을 위한 가변 길이 코드북 생성 알고리즘
- world model과 cohort model을 사용한 혼합 구조 화자 모델링 기술
- 사용자 이동성을 고려한 채널 불일치 보상 알고리즘
- 화자의 몸 상태, 주변 환경 등 화자 특성 변화 요소 Normalizing 기술
- Speaker Adaptation
- 시간의 변화에 따른 장기간 음성 변화 특징 예측 모델링 기술
- Text-dependent / Text-independent 화자 인식 기술
- 지정된 문맥을 발성하는 문맥 종속형 화자인식 시스템
- 사용자 임의의 암호를 발성하는 User-selectable Password 화자인식 시스템
- 사용자의 장구간 발성음에서 특징을 추출하여 인식하는 불특정 문맥 화자인식 시스템